(Krippendorff’s α: 일련의 분석 단위를 코딩 할 때 달성 된 합의에 대한 통계 측정)
Attention label
Hate speech에서 가장 많이 나온 단어 3개: nigger, kike, moslems
Offensive speech에서 가장 많이 나온 단어 3개: retarted, bitch, white
attention해야 할 단어를 1/ 나머지를 0으로 하여 각 문장의 attention vector를 만든 뒤 각 annotator별로 생성한 vector들을 평균하고, softmax 함수를 취해 각 post의 attention vector(Ground truth)가 되도록 함 (????? ground truth가 annotator에 의해 생성되는 것인가 model에 의해 생성되는 것인가 헷갈림..)
이를 통해 rationale token과 non-rationale 토큰 간의 value 차이가 적어질 수 있기 때문에 softmax 함수에 temperature parameter(τ )를 추가하여 rationale token에 조금 더 집중된 probability를 계산하게 함
만약 문장의 label이 normal일 경우, attention vector의 요소들을 1/(문장길이)로 채움
<Matrix for evaluation>
subgroup AUC: 문장의 target에 따른 toxicity 라벨을 잘 분류했는지
(distinguishing the toxic and normal posts specific to the community)
BPSN: target이 명시된 normal sentence와 target이 명시되지 않은 hate speech를 잘 구분하는지
(A higher value means that a model is less likely to confuse between the normal post that mentions the community with a toxic post that does not)
GMB: subgroup의 편향과 관련된 평가 지표
This metric combines the peridentify Bias AUCs into one overall measure as
where, Mp = the p th power-mean function, ms = the bias metric m calculated for subgroup s and N = number of identity subgroups (10). We use p = −5 as was also done in the competition. We report the following three metrics for our dataset. - GMB-Subgroup-AUC: GMB AUC with Subgroup AUC as the bias metric. - GMB-BPSN-AUC: GMB AUC with BPSN AUC as the bias metric. - GMB-BNSP-AUC: GMB AUC with BNSP AUC as the bias metric.
Plausibility: 얼마나 사람에게 설득력이 있는가? (얼마나 사람과 유사한 근거를 활용하여 판단했는가 정도인듯)
Faithfulness: 모델의 추론 과정을 얼마나 정확하게 반영했는가? (Comprehensiveness (rationales가 얼마나 prediction에 영향을 미쳤는가) + Sufficiency (설명력이 높다고 판단된 rationales가 얼마나 prediction을 하기에 적합한지))
we create a contrast example x˜i , for each post xi , where x˜i is calculated by removing the predicted rationales ri 8 from xi . Let m(xi)j be the original prediction probability provided by a model m for the predicted class j. Then we define m(xi\ri)j as the predicted probability of x˜i (= xi\ri) by the model m for the class j. We would expect the model prediction to be lower on removing the rationales. We can measure this as follows – comprehensiveness = m(xi)j −m(xi\ri)j . Sufficiency = m(xi)j − m(ri)j .
<Model details>
각 모델은 문장별 label만 있는 dataset과 attention label이 추가된 dataset 두 가지 version으로 test됨
m = 입력 문장의 토큰 개수
CNN-GRU : Detecting Hate Speech on Twitter Using a Convolution-GRU Based Deep Neural Network(2018) 논문 참고
BiRNN: Bidirectional recurrent neural networks(1997) 논문 참고
BiRNN with attention: Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling(https://arxiv.org/pdf/1609.01454.pdf , 2016) 논문 참고
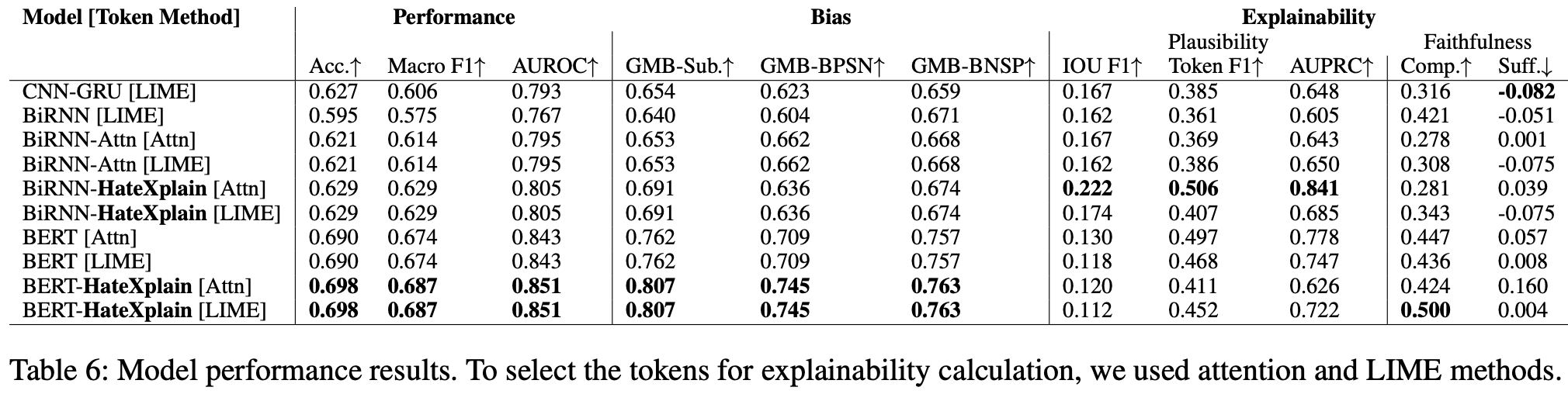
<Results>
각 모델별 구조 설명은 논문 6 & 11page 참고/ <Model>-HateXplain은 attention vector가 지도 학습된 모델
*LIME (https://arxiv.org/pdf/1602.04938.pdf): 예측에 기여하거나 반하는 설명자를 확인하기 위해 입력값을 교란하여 모델의 예측이 어떻게 바뀌는 지를 확인. 본 논문에서는 attnetion vector의 토큰 조합을 다르게 함으로써 어떤 토큰의 설명력이 가장 높은지를 확인 한 것으로 이해됨.
1. 교란 인스턴스를 만듦 2. 픽셀 - 각 인스턴스에 대한 예측 확률값에 대해 라소회귀 실행하여 K개의 픽셀 선택 3. 가장 높은 양의 계수를 가지는 픽셀이 설명 역할을 함 (개구리 얼굴), 나머지 선택되지 못한 픽셀들은 grey 처리 (출처: https://blogs.sas.com/content/saskorea/2018/12/10/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-%ED%95%B4%EC%84%9D%EB%A0%A5-%EC%8B%9C%EB%A6%AC%EC%A6%88-4%ED%83%84-%EB%9D%BC%EC%9E%84lime%EC%9C%BC%EB%A1%9C-%EB%AA%A8%EB%8D%B8-%ED%95%B4%EC%84%9D%EB%A0%A5/)
대체적으로 human rationales를 사용한 -HateXplain 모델이 performance가 더 좋고, 편향에도 강함 (과연 통계적으로 유의한 정도의 향상인지는 의문)
BERT 모델에서는 HateXplain의 plausibility가 지도학습을 하지 않은 모델보다 더 낮음
<Limitations>
문맥, 작성자의 프로필이나 성별 등 관련 데이터를 활용하지 못함
영어에만 한정된 연구
offensive speech를 hate speech로 구분할 것인가 아닌가도 결정 필요할 듯