-
[장기기억 챗봇] 챗봇, 금붕어 기억력에서 벗어나다: Introduction to Blenderbot 2.0Project 2021. 8. 9. 01:27728x90반응형

Facebook AI Reasearch(FAIR)에서 7/16일 인터넷 검색을 통해 장기기억과 실시간 인터넷 검색을 통해 정교한 대화를 할 수 있는 chatbot인 Blenderbot 2.0을 발표했다.
인터넷 검색을 활용함으로써 모델은 훈련된 정보가 아닌 가장 최신의 정보를 전달할 수 있으며, 대부분의 주제에 대해 대화가 가능하게되었다. 또한 대화 중 필요한 정보를 장기기억에 저장함으로써 몇 개월 동안 이어지는 대화에도 저장한 지식을 계속 활용할 수 있도록 했다 - 한 달전에 어떤 사용자와 박지성에 대해 얘기했다면, 이를 통해 이 후 '축구'라는 주제를 대화에서 언급할 수 있다.
이 때 데이터는 각 대화하는 상대마다 따로 저장되기 때문에 한 대화에서 저장된 정보는 다른 대화에서 사용되지 않는다.
정보는 항상 생성되고 변화하기때문에 (특히 요즘 시대에) 최신 정보를 모델에 timely 반영하기 어려우므로 인터넷 검색을 통해 학습된 데이터 뿐 아니라 검색된 정보를 응답에 반영하고, 최신 정보에 바로 접근 할 수 있게 했으며 large model을 계속해서 훈련시켜야하는 어려움에서 벗어났다는 idea가 가장 큰 특징이다.
아직 영어로밖에 훈련되지 않아 영어 기반 검색 결과밖에 참조하지 못하지만 multi-modal 도 계속 개발 중이며 이전 모델의 한계점들을 많이 극복했다는 점에서 시사하는 바가 크다.
GPT-3나 Blenderbot 1.0과 같은 기존 챗봇 모델들은 현재 진행되고 있는 대화에서는 우수한 성능을 보이지만 대화의 내용을 오래 기억하지 못하고(Goldfish memory) 이전에 훈련된 데이터로만 대화가 이루어지는 정적인 기억력을 가지는 한계가 있었다. 새로운 정보를 저장하지 못한다는 단점은 곧 최신 정보를 반영하지 못한다는 점으로, Tom Brady라는 미식 축구 선수가 2020년 새로운 팀으로 이적했으나 GPT3는 해당 정보를 알지 못하고 이전 팀인 뉴잉글랜드 패트리어츠 팀 소속으로 소개하는 사례, 2021년 방영된 드라마인 Wandavision에 대해 Blenderbot 1.0이 'I've never heard about it'이라고 대답하는 사례를 예시로 들고 있다.

출처: https://parl.ai/projects/blenderbot2/ 
출처: https://parl.ai/projects/blenderbot2/ 이 챗봇은 하기 논문을 기반으로 연구되었다.
1. Internet-Augmented Dialogue Generation
2. Beyond Goldfish Memory: Long-Term Open-Domain Conversation
Architecture
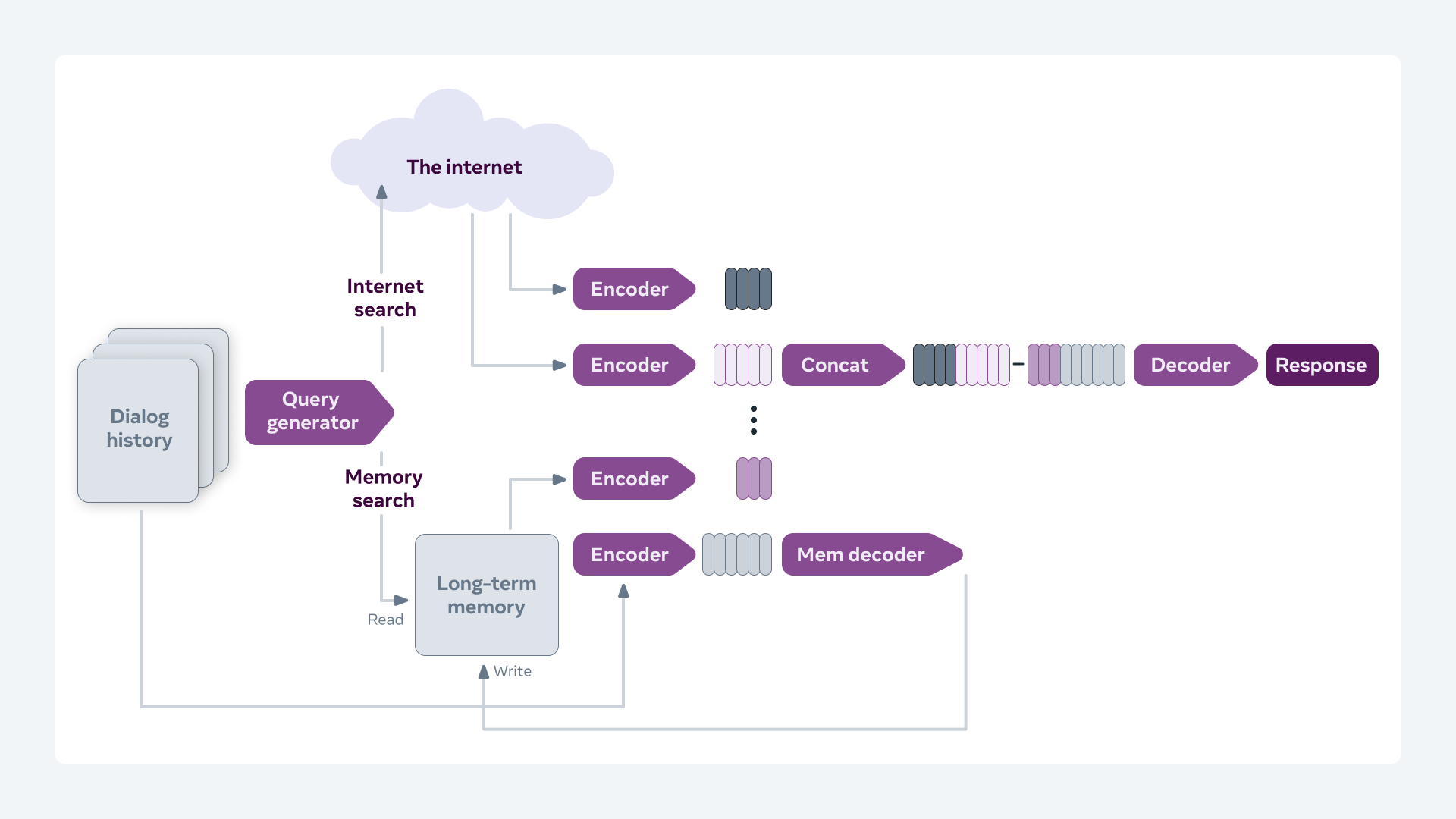
출처: https://parl.ai/projects/blenderbot2/ 기본적으로 Blenderbot 1.0 구조 + Additional neural network 이다.
여기서 Additional neural network는 장기 기억 저장소에서 어떤 정보를 꺼내올지, 현재 대화에서 어떤 정보를 장기 기억소로 저장할지를 찾아내는 역할을 한다. (저 그림에서 Encoder+Memdecoder부분을 얘기하는 것 같은데 정확한 건 다시 글을 읽어봐야 할 것 같다..)
사용자와 나눈 대화 history는 Blenderbot 2.0의 Encoder와 Mem(ory) Decoder를 거쳐 장기 기억 저장소에 저장된다.
대화 중에는 Query encoder를 통해 생성된 검색 쿼리를 통해 인터넷 검색 및 장기 기억 저장소의 정보에 접근하여 필요한 정보를 Encoder에 전달한다.
Encoder에서는 인터넷 검색 결과와 장기 기억 저장소에서 찾은 문맥정보를 받고, Encoder의 출력값은 Concatenate되어 Decoder로 입력된다.
Decoder는 Fusion-in-Decoder 방법을 통해 Encoding된 지식을 고려해 응답을 생성하고 장기기억 저장소에서 어떤 정보를 가져와 추가할 지 결정한다.

Search에서 Encoder로 입력되는 결과를 생성하는 과정은 Facebook의 Retrieval Augmented Generation(RAG)을 기반으로 한 모델을 사용하는데, 기본 seq2seq 모델 인풋에 문맥 정보를 반영해 특정 도메인에 특화된 결과를 더 잘 얻을 수 있다고 한다.
구조는 크게 Retriever(검색기)와 Generator로 구성된다.
Retriever: Poly Encoder 구조 사용
Wikipidia로 학습된 document embedding에 대한 인덱스를 가지고 있다.
Query encoder를 통해 생성된 query와 가까운 documment embedding을 찾음 (=문맥정보)
해당 정보를 Encoder로 입력시킨다.


Generator: 원본입력과 문맥정보가 연결된 데이터를 입력으로 받아 하나의 target sequence를 만들어 냄
Generator에서는 marginalize 과정을 수행하는데, joint distribution에서 한 가지 변수에 대한 확률값을 추정하기 위해 나머지 변수를 모두 적분해나가는 과정이다. 결과값으로 가장 높은 확률값이 도출 된다.

https://ai.facebook.com/1319742961447503/videos/147222164163605/
Training dataset
Wizard of the Internet: 인터넷 검색의 새로운 정보로 사람 대화를 증강
쿼리를 생성하는 방법과 검색 결과에 따른 응답 관리 기능을 제공
Multi-session chat: 대화의 지식을 참조하는 사람과의 긴 대화
장기 기억 저장소에 새로운 지식을 저장하는 chatbot과 주어진 기억과 관련된 응답을 제공하는 것에 대한 supervision 기능을 제공
Evaluation
이미 Blenderbot 1.0에서 Google의 Meena와 Microsoft의 DialogGPT보다 훨씬 우수한 성능을 내는 것을 증명했기 때문에 2.0은 1.0을 기준으로 얼마나 multi-session에서 장기 대화를 잘 수행하느냐, 대화에서 검색한 지식을 잘 활용하느냐를 기준으로 평가했다.
˙호응도(engagingness score, 이전 대화에서 중단되었던 부분부터 대화를 이어나가는 성능): 17% 향상
˙이전 대화 사용률(이전 대화의 맥락을 고려한 평가): 55% 향상
라는 결과를 통해 Blenderbot 1.0보다 더 오랜 시간 동안 더 정확한 대화를 이어나간다는 것을 보여주었다.
특히 chatbot의 취약점으로 꼽히는 'hallucinate knowledge'(개인적으로 한국어로 환각기억이라고 번역되는거 너무 싫다) 문제를 9.1%에서 3.0%로 감소시켰고, 사실적으로 일관된(factually consistent) 대화는 12% 더 자주했다.
여기에서 hallucinate knowledge란 chatbot이 text generation을 하는 과정에서 잘못된 정보를 답변에 포함하게 되는 현상을 일컫는다. 하기 예시에서 실제로는 사실이 아닌(yellow highlighted된 부분) 정보들을 사실인 것 처럼 답변하는 것을 볼 수 있다.

출처: Retrieval Augmentation Reduces Hallucination in Conversation 논문 (https://arxiv.org/pdf/2104.07567.pdf) Safety
챗봇이 unsafe하거나 offensive한 text를 generate하지 않게 하기 위해 break-in safety와 robertness to difficult prompts라 명명한 방법들을 고안했다. 여기서 prompt는 대화 상대방이 chatbot으로부터 적절하지 않은 발언을 이끌어내기 위해 의도적으로하는 질문을 뜻한다.
(Safety라고 이름을 붙인 이유는 이용자들을 공격적인 말에서 보호한다는 의미)
방대한 연구를 수행했고, 위에서 언급한 두 가지 기술로 기존보다 훨씬 우수한 성과를 냈으나 아직 완전하지 않은 상태이며 특히 Blenderbot 2.0은 인터넷 검색을 활용하기 때문에 해당 문제가 더 중요하게 다루어지고 있다.
추가로 해당 모델이 어떻게 각 기능들을 구현했는지 코드 분석이 필요할 것 같다. 2.0개발에 참고했다고 하는 두 개 논문과 Blenderbot 1.0 논문을 읽어봐야하지 않을까 싶다.
LT memory chatbot 개발의 목적을 추억을 소환해서 조금 더 맛깔나는 현재의 대화를 하는데 두는 것 보다 어떻게 하면 모델이 일관적인 대답을 할 수 있을 지 - 예를 들어 한 달전에는 favorite musician이 에미넴이라고 했다가 갑자기 Actually I'm not a fan of hip-hop이라는 문장을 생성해 내지 않게 -, 그리고 상대방이 했던 말을 잘 기억하도록 구축하는 데 두는 것이 우선이지 않을까 싶다.
만약 개발하고자 하는 chatbot의 대화 목적이 감성 대화라면 사실 인터넷 검색 기능이 크게 필요할까 싶다 (해당 챗봇을 정보 검색의 목적으로 사용하지 않으므로).
728x90반응형