-
[논문리뷰보다는 해석에 가까운] GPT-1 : Improving Language Understanding by Generative Pre-TrainingDeep Learning 2021. 8. 22. 21:14728x90반응형
2018
https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
해당 논문은 OpenAI에서 발표한 NLP모델인 GPT 시리즈 중 첫 번째 모델인 GPT-1에 대한 논문이다.
본 포스팅은 논문 내용 뿐 아니라 이해에 도움이 되는 추가적인 설명도 포함하고 있다.
Introduction
딥러닝 모델은 대부분 지도학습을하기 때문에 레이블링이 필요하지만, 구할 수 있는 대부분의 데이터는 레이블링이 되어있지 않다는 한계가 있다. 그래서 본 논문에서는 레이블링이 되어있지 않은 데이터로 모델을 학습시켜 레이블링 데이터를 이용했을 때의 단점을 극복하고 사람이 알지 못하는 데이터의 특성까지 모델이 학습하게 하고, 이 후 작은 수정만으로 효과적인 transfer를 하게 함으로써 높은 성능을 달성할 수 있다는 것을 입증했다.
레이블링이 되어있지 않은 데이터로 학습시키는 것은 두 가지의 challenge가 있다.
1. 결과물을 transfer하기 위한 Text representation을 학습시키는 것에 어떤 optimization objective가 효과적인지 불분명하다. 최근 연구들을 통해 language modeling, machine translation, discourse coherence와 같은 task들이 다른 task들보다 이 방법을 사용했을 때 효과적임을 찾아냈다.
2. 학습된 특징을 target task에 어떤 방식으로 transfer할지 명확히 정의되어있지않다. 그래서 여러 연구에서 모델 구조를 task에 따라 수정하거나 복잡한 learning scheme을 거치거나 learning objective를 추가하는 방법들을 시도해 왔다.
본 연구에서는 unsupervised pre-training과 supervised fine-tuning을 합친 준 지도학습 방식을 제안한다. 최종 목표는 일반적으로 높은 성능을 낼 수 있는 특성을 학습시켜 이 후 조금의 변화를 통해 다양한 task에 적용할 수 있는 모델을 만드는 것이다. 이를 위해 대량의 unlabeled data와 task에 알맞는 labeled data가 있다고 가정하고, 해당 모델은 레이블링 되지 않은 데이터로 모델의 초기 파라미터를 학습하고, 이렇게 최적화된 파라미터를 원하는 목적에 맞게 labeled data로 추가 학습시킨다.
모델 구조는 Transformer를 사용했다. Transformer는 RNN 기계번역이나 문서 생성, 구문 분석과 같은 task에서 강력한 성능을 보인다. 또한 Transformer구조를 사용함으로써 RNN같은 모델보다 텍스트에서의 장기 의존성 문제를 더 잘 처리할 수 있었고, 다양한 테스크에서 최소한의 fine-tuning을 통해 transfer가 가능하게 했다. 이를 확인하기 위해 해당 모델을 natural language inference(자연어 추론), question answering(대답 추론), semantic similarity(의미적 유사도 분석), text classification(텍스트 분류)의 네 가지 task에서 성능을 측정했다.
Related Works
NLP에서의 준지도학습
초기의 연구들은 unlabeled data로 모델이 단어 또는 구문 수준의 통계값들을 연산하고 이를 이후 지도 학습의 특성으로 사용하는 방식을 사용했다. 지난 몇 년간 이루어진 연구들은 word2vec, GloVe와 같은 unlabeled 코퍼스를 이용한 훈련을 통해 단어 임베딩을 사용하는 방식들이 높은 성능을 낸다는 것을 입증했다. 하지만 이 연구들은 주로 단어 단위의 정보를 학습했고, 본 연구에서는 더 높은 차원의 의미를 포착해내는 방법을 시도했다.
Unsupervised pre-training
Unsupervised pre-training의 목적은 이 후 수행될 supervised learning에 좋은 초기화 포인트를 제공하는 것이다. 이전에는 이미지 분류, 회귀 문제 등에 이 방법이 사용됐었다. 후속 연구에서 Pre-training 기법은 정규화 작용을 하여 딥러닝 모델을 더 잘 일반화하는 것이 밝혀졌고, 최근의 연구에서 이 기법은 이미지 분류, 발언 인식, 기계 번역 등의 다양한 task에서 딥러닝 모델이 더 잘 훈련될 수 있게 하기 위해 사용되었다.
이번 연구와 가장 유사한 방식으로는 UMLFit과 Semi-supervised squence labeling이 있다. 하지만 이 방식들은 LSTM model을 사용하여 예측 사이즈를 짧은 범위로 제한한다. 반면, transformer구조는 더 긴 길이의 언어적인 구조를 포착할 수 있고 generative pre-training방법은 transfer시 아주 작은 변화만을 필요로 한다는 것이 밝혀졌다.
Auxiliary training objectives
보조적으로 비지도 학습 목적함수를 추가하는 것 또한 준지도학습의 형태 중 하나이다. 하지만 본 연구에서 시도한 결과 unsupervised pre-training에서 이미 target task와 관련있는 언어적 특성을 충분히 학습했음을 확인했다.
Framework
GPT 모델은 첫 번째 훈련 단계에서 high-capacity language model을 학습하고, 두 번째로 특정 task에 맞는 labeled data로 fine-tuning하는 단계를 거친다.
Unsupervised pre-training
토큰으로 이루어진 코퍼스 $\upsilon = \left \{ u_{1},u_{2},...,u_{n} \right \}$ 가 주어지면 다음의 likelihood를 최대화하는 standard langugage modeling objective를 사용한다. 이 때 k는 context window의 크기이고, $\Theta$는 신경망 모델의 파라미터다. 해당 파라미터는 SGD를 통해 훈련된다.
$L1(\upsilon ) = \sum_{i}log P(u_{i}|u_{i-k},...,u_{i-1};\Theta )$
본 논문에서는 학습을 위한 languge model로 multi-layer Transformer decoder를 사용했다. 이 모델은 position-wise feedforward 레이어에 따라 입력 토큰의 타켓 토큰에 대한 출력값의 분포를 생성하기 위해 multi-head self-attention 구조를 적용했다.
$U= \left \{ u_{-k},...,u_{-1} \right \}$가 토큰의 문맥 벡터이고 n이 layer의 수, $W_{e}$는 토큰 임베딩 행렬, $W_{p}$가 포지션 임베딩 행렬일 때, 다음의 구조를 가진다.
$h_{0} = UW{e} + W_{p}$
$h_{l} = $transformerblock$(h_{l-1})\forall i \in [1,n]$
$P(u) = softmax(h_{n} W_{e}^{T})$
Supervised fine-tuning
Language model의 objective에 대해 모델을 pre-training 한 후, 각 Instance가 label y에 따른 입력 토큰 $x^1,...,x^m$ 로 이루어져 있는 labeled dataset C를 가지는 target task에 대해 파라미터를 조정한다. 이 때, 예측값을 얻기 위해 Pre-train된 transformer 모델의 마지막 블록의 activation $h_{l}^{m}$을 input으로 하는 linear layer를 추가한다.
$P(y|x^{1},...,x^{m})=softmax(h_{l}^{m}W_{y})$
이 레이어는 다음의 목적함수를 최대화하는 방향으로 학습된다.
$L_{2}(C) =\sum_{(x,y)}logP(y|x^{1},...,x^{m})$
추가적으로 fine-tuning에 보조 목적(auxiliary objective)로써 language model을 추가하는 것이 지도학습 모델의 일반화를 향상시키고 모델이 빠르게 수렴하는 데 도움을 주는 것을 확인했다. 이 auxiliary objective에서 연구자가 다음의 목적 함수의 가중치 $\lambda$를 최적화한다 (하이퍼파라미터).
$L_{3} = L_{2}(C) + \lambda * L_{1}(C)$
전체적으로 fine-tunin과정에서 추가로 학습해야하는 파라미터는 $W_{y}$와 delimiter 토큰에 대한 임베딩 밖에 없다.
각 태스크에 해당하는 입력의 변형은 하기 그림으로 확인할 수 있다.

Transfer learning을 사용하지 않고 새로운 작업마다 다른 구조의 모델을 소개했던 이전 연구와 달리 GPT모델은 순회 접근법을 사용하여(traversal-style approach) 구조화된 입력을 pre-trained모델이 사용할 수 있는 순서화된 시퀀스로 변환함으로써 약간의 변형만으로 여러가지 task에 적용할 수 있게 되었다. 모든 변형은 무작위로 초기화된 start token <s>와 end token<e>를 포함한다.
Textual entailment task: premise p와 hypothesis h 토큰 시퀀스를 delimiter token ($)로 concat한다.
Similarity task: 유사도 측정 task는 비교되는 두 문장의 순서가 없기 때문에 가능한 문장 순서를 모두 포함하도록 입력 시퀀스를 delimiter token과 함께 수정하고, 두 문장의 representation $h_{l}^{m}$을 생성하기 위해 각각을 독립적으로 처리한 후 linear layer에 들어가기 전에 더한다.
Question Answering and Commonsense Reasoning: context document z와 question q, 가능한 답변 set인 $a_{k}$가 주어지고 document context와 question을 delimiter token을 사용해 각 답변과 concat한다. 형태는 $[z;q;\$;a_{k}]$와 같다. 각 시퀀스 별로 독립적으로 처리되며 최종 출력된 가능한 답변의 분포를 생성하기 위해 softmax layer에 전달된다.
Experiments
Setup
Pre-training 데이터로 다양한 장르의 출간되지 않은 책 7,000여 권이상이 포함되어 있는 BookCorpus 데이터셋을 사용했다.
모델 구조는 masked self attention head가 포함된 Transformer의 decoder만 가져왔으며 12개 layer를 사용했다 (768 demensional states and 12 attention heads). Optimization으로는 learning rate가 조정된 Adam을 사용했고 batch size는 64, epoch은 100회 동안 훈련시켰다.
인코딩은 BPE(Byte pair encoding)방식을, activation으로는 GELU(Gaussian Error Linear Unit)를 사용하되 기존 연구에서 제안된 sinusoidal version이 아닌 학습된 위치 임베딩(position embedding)을 적용했다. 전처리는 fifty liabrary를 이용했으며 구두점, white space를 표준화하고 spaCy tokenizer를 사용했다.
(자세한 훈련 setting은 논문 5page - Model specifications 참조)
Fine-tuning에는 unsupervised pre-training에 사용한 하이퍼파라미터를 그대로 사용하되 learning rate를 6.25e-5로 수정하고 분류 task의 경우 dropout을 추가했다. Epoch 3회, batchsize 32로 짧게 훈련했으나 대부분의 task에서 충분한 것으로 확인됐다.
Supervised fine-tuning

Supervised fine-tuning 단계에서 각 task에 사용된 dataset 목록 Natural Language Inference (자연어 추론, NLI)
NLI는 recognizing textual entailment와 같은 task로 문장 쌍을 읽고 두 문장의 관계를 수반하는 사이인지(entailment), 모순된 사이인지(Contradiction), 중립 관계인지(neutral)를 판단하는 것이다.

RTE의 예시 (출처: https://galsang.github.io/files/An%20introduction%20to%20Natural%20Language%20Inference_Taeuk%20KIm.pdf) 해당 task는 어휘 및 구문 모호성과 같은 다양한 문제들 때문에 여전히 어려운 과제로 남아있다.
본 연구에서는 이미지 캡션(SNLI), 정부 리포트(MNLI), 위키피디아 기사(QNLI), Science exams(SciTail), 뉴스 기사(RTE)로 각 task별 성능을 측정 및 비교했다.

위의 결과표를 보면 RTE를 제외한 네 개의 데이터 셋에서 다른 모델보다 우수한 정확도를 달성한 것을 볼 수 있다.
Question answering and commonsense reasoning (질문 대답 & 상식 추론)
해당 실험에는 긴 context가 포함된 데이터셋을 평가에 사용함으로써 제안된 모델 구조가 long-range contexts도 효과적으로 처리함을 보여주었다.

Semmantic Similarity (의미 유사성 분석)
Paraphrase detection이라고도 불리는 Semantic similarity task에서는 입력된 두 개의 문장이 의미적으로 같은지를 예측한다. 해당 task는 개념의 표현을 인식하고 부정을 이해하며 구문적 모호성을 처리하는 것에 대한 어려움이 있다.
평가에 사용된 세 개의 데이터셋 중 두 개에서 최고 성능을 달성했다.
Classification
분류 task로는 CoLA(The Corpus of Linguistic Acceptability)와 SST-2(The Stanford Sentiment Treebank)를 사용했다.
CoLA는 입력 문장이 문법적으로 옳은지를 binary로 판별하는 dataset이다(언어학적으로 acceptable한지).
SST-2는 영화 코멘트 데이터의 긍/부정 binary로 분류하는 데이터셋이다.
GLUE(General Language Understanding Evaluation)은 다양하고 해결하기 어려운
9개11개(2019년 9월 기준 GLUE 증가)의 task로 이루어진 데이터셋으로, 모델의 자연어 이해 능력을 평가하기 위해 고안되었다. 자연어 task는 서로 연결되어있기 때문에, 연구자는 특정 task를 목적으로 모델을 개발 또는 사용하더라도 해당 모델 자체는 전반적으로 자연어를 이해하는 성능이 좋아야한다. 따라서 GLUE 벤치마크에서 높은 성능을 낸다는 것은 해당 모델이 자연어를 일반적으로 잘 이해하고, 전이학습 시 특정 task에도 성능을 잘 낼 것이라는 의미를 가진다.
전체적으로 GPT 모델은 12개의 dataset 중 9개의 dataset에서 SOTA를 달성했으며, 5.7k의 데이터로 이루어진 작은 데이터셋부터 550k개의 데이터가 있는 큰 데이터셋까지 좋은 성능을 낸다는 것을 확인했다.
Analysis
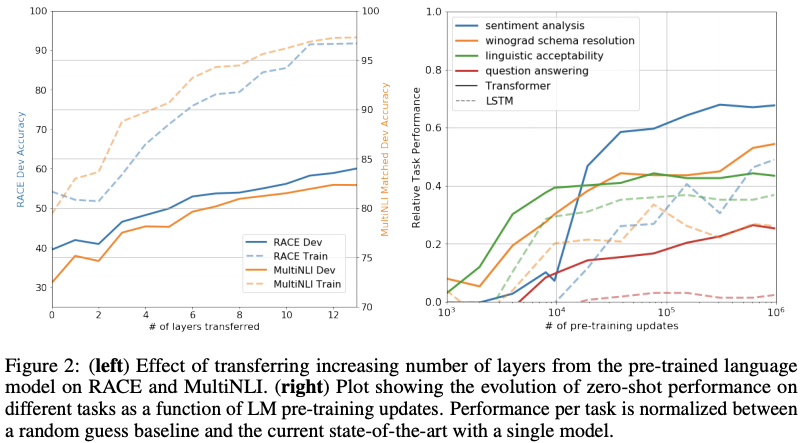
Impact of number of layers transferred
하단 왼쪽 그림은 MultiNLI와 RACE dataset에서 transfer된 layer의 개수에 따른 모델 performance에 대한 영향을 표현한 것이다.
MultiNLI에서 full transfer를 했을 때 각 transfomer 레이어가 9%까지 추가 향상을 이끌어내는 것을 볼 수 있다. 이것은 pre-train된 모델의 각 레이어가 target task를 수행하는데 유용한 정보를 포함하고 있다는 것을 의미한다.
Zero-shot Behaviours
본 연구는 기본 generative model이 language model의 capability를 향상시키기 위해 많은 task를 수행하는 법을 배우고 transformer의 구조화된 attentional memory가 LSTM에 비해 transfer에 도움이 된다는 것을 가정했다. 따라서 왜 transformer의 language model pre-training이 효과적인지 이해하기 위해 기본 generative model을 supervised fine-tuning을 하지 않았을 때 task에 대한 성능이 어떤지를 확인했다.
하단 오른쪽 그림에서 확인할 수 있듯, generative model의 performance가 안정적이고 지속적으로 증가했으며 이를 통해 generative pre-training이 다양한 task에 관련된 정보를 학습하는데 도움을 준다는 것을 알 수 있다. 또한 LSTM 모델이 더 큰 분산(variance)을 보이는 것을 통해 transformer 구조의 inductive bias(학습 시에는 만나보지 않았던 상황에 대해 정확한 예측을 하기 위해 사용하는 추가적인 가정 - 일반화가 잘 되었는지)가 transfer에 도움이 된다는 것을 입증했다.
(* inductive bias에 대한 추가 설명)
Ablation studies

앞서 소개한 auxiliary object에 대한 효과를 확인할 수 있다.
NLI(Natural language inference)와 QQP(Quora Question Pairs) 데이터 셋에서 성능을 높이는 데 도움이 되었다. 해당 실험을 통해 auxiliary object가 큰 데이터 셋에서는 성능 향상에 도움이 되지만 작은 데이터 셋에서는 아님을 알 수 있었다.
추가로 transformer구조 대신 LSTM 모델을 사용해 보았고, MRPC 데이터 셋을 제외하고는 모두 transformer보다 낮은 성능을 기록했다.
마지막으로 pre-training을 했을 때 보다 하지 않았을 때 전체적으로 성능이 감소하는 것을 보았다.
Conclusion
본 연구에서는 generative pre-training과 discriminative fine-tuning을 통해 모델이 특정 task에 종속되지 않고 일반적으로 성능을 잘 낼 수 있음을 확인했다. 길고 연속된 텍스트로 이루어진 다양한 코퍼스로 사전 학습을 함으로써 모델이 장기의존성과 world knowledge(?)를 잘 처리할 수 있는 능력을 가질 수 있었고, 이로 인해 모델이 전이 학습에서 discriminative task를 잘 해결할 수 있었다.
728x90반응형'Deep Learning' 카테고리의 다른 글