-
[논문리뷰보다는 해석에 가까운] AngryBERT: Joint Learning Target andEmotion for Hate Speech DetectionDeep Learning 2021. 6. 25. 20:05728x90반응형
https://arxiv.org/pdf/2103.11800.pdf
Mar-2021 발행
<Abstract / Introduction>
기존 진행된 연구의 한계
지도학습을 사용하여 이미 Annotate된 dataset에 과하게 의존
→ 불균형 dataset: 혐오표현 학습을 위한 training sample이 너무 적음
→ 현재 사용되고 있는 data augmentation 방법은 성능 향상에 미치는 정도가 미미함
해당 문제를 개선하기 위해 본 논문에서는 1차 task로 hate speech detection을 하되 2차 task로 감정 분류와 타겟 인식을 함께 수행하는 Angry BERT 모델을 제시
Multi-task learning: 여러 관련된 task에서 유용한 정보들을 활용함으로써 task의 일반화 성능을 높이는 기계학습 방법
AngryBERT에서는 감정분류와 hateful target을 인식하는 task를 secondary task로 지정하는 방법으로 활용
- 이전에도 abusive speech detection에 MTL방법을 사용한 연구가 있었으나(Bridging the gaps: Multi task learning for domain transfer of hate speech detection - 2018) 해당 연구에서는 모든 과제가 동일한 fully shared features를 사용하는 MTL 모델을 사용했으며 hate speech detection task와 dataset에만 집중.
- 하지만 본 연구에서는 모델이 각 작업별 dependent feature와 shared(변하지 않는) feature를 구분하여 학습을 수행할 수 있도록 shared-private scheme으로 설계하였으며, 관련된 task와 dataset을 모두 활용함으로서 primary task인 hate speech detection을 더 잘 수행할 수 있도록 함.
- 비슷한 연구 방법을 수행한 사례도 있으나(Joint modelling of emotion and abusive language detection - 2020) 해당 논문에서는 shared layer에 Bi-LSTM encoder를, intra-task 학습에는 attention매커니즘을 사용했고, secondary task로 감정 분류만 수행. 하지만 본 논문에서는 shared layer에 pre-trained된 BERT모델을 사용했으며, secondary task에 target identification을 추가.
<Dataset and Tasks>
MTL 방법에서는 task간의 관련성이 모델의 성능과 안정화에 영향을 많이 미침
연구자는 hate speech를 (1)특정 대상에 대한 (2)부정적인 말로 정의를 했음.
따라서 primary task는 hate speech detection,
secondary task는 (1)에 따라 target identification, (2)는 주로 부정적인 감정을 포함하므로 emotion classification으로 정함.

* Hate speech detection
WZ-LS
DT: 이전 논문에 나와있는 twitter API와 ID를 사용하여 동일하게 데이터를 수집하려 했으나 일부 tweet이 삭제되어 완전히 동일한 dataset을 확보하지는 못함.
FOUNTA: 이전 논문에 나와 있는 dataset에서 중복된 tweet들을 제거하기 위해 retweet을 포함하지 않음
* Emotion classification
SemEval_A
*Target identification
HateLingo: 특정 Target group을 검출하기 위해 사용
OffensEval_C: Target group이 개인인지 그룹인지 확인하기 위해 사용
<Proposed Model>
Structure
Si = {s i 1 , si 2 . . . , si n}, i ∈ {1, 2, . . . , K}
C = {c i 1 , ci 2 . . . , ci m}
K = the number of tasks
n = length of the sentence
C = the prediction result of input text for task i
m = the number of classes for task i

Shared layer: 모든 task에 공유될 수 있는 feature를 학습
기본 BERT tokenizer와 pre-train된 BERT 모델을 사용해 임베딩
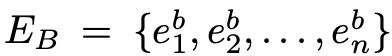

[CLS]토큰부터나온 output을 shared layer의 representation으로 함(=o1 ∈ Rd)

Private layer: 각 task에 대해 독립적인 feature를 학습
각 단어의 문맥을 최대한 활용하기위해 Bi-LSTM모델 사용
GloVe 사용해 임베딩


마지막 은닉층에서 순방향과 역방향의 output을 concat한 최종 output을 Private layer의 latent representation으로 함(=hn ∈ Rd)

Gate Fusion: shared layer의 output과 private layer의 output 벡터에 대해 다른 weight를 부여함으로써 각 output의 융합 비율을 조정
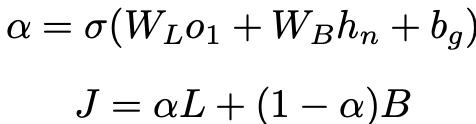
모델은 WL, WB and bg를 학습
알파는 o1, hn과 같은 차원
Classification layer: J에 ReLU와 Softmax함수를 적용

Loss: Private layer에서는 cross entropy사용하고 Shared layer에서는 각 작업에 대한 loss에 가중치를 부여하여 합산
<Experiments>

Hybrid CNN: One-step and two-step classification for abusive language detection on twitter(https://arxiv.org/pdf/1706.01206.pdf) 논문에서 사용한 모델

CNN-GRU: Detecting hate speech on twitter using a convolution-gru based deep neural network 논문에서 사용한 모델

Deep Hate: Deephate: Hate speech detection via multifaceted text representations 논문에서 사용한 모델

SP-MTL: Recurrent neural network for text classification with multi-task learning(https://arxiv.org/pdf/1605.05101.pdf) 논문에서 사용한 모델(LSTM 기반 MTL 구조)
MT-DNN: Multi-task deep neural networks for natural language understanding(https://arxiv.org/pdf/1901.11504.pdf) 논문에서 사용한 모델

MTL-Gated Encoder: Joint modelling of emotion and abusive language detection(https://arxiv.org/pdf/2005.14028.pdf) 논문에서 사용한 모델 (stacked Bi-LSTM 구조의 인코더 + Attention, sencondary task로 emotion detection만 학습)
결과
MTL모델이 대부분의 dataset에서 single task model보다 높은 score를 냄. 그 중에서도 Angry BERT모델이 모든 dataset에서 F1 score가 가장 높게 나옴.
<Ablation Study>

Primary task에 사용된 데이터의 종류마다 결과가 좋은 조합이 다름.
전체적으로 OffenseEval_C(target identification task)가 들어간 조합이 score가 높음
어떤 조합이든 single task detection보다는 성능이 높음
<Case studies>

. 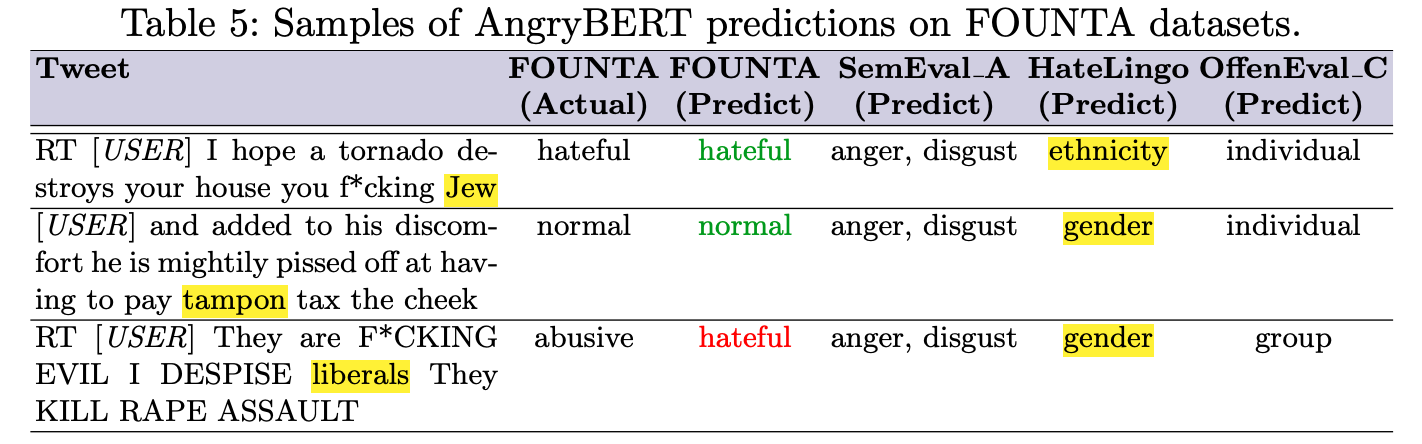
Green font: Correct prediction/ Red font: Incorrect prediction/ Highlighted: the keywords in the given post that might have influenced the predicted target in HateLingo dataset Hate speech로 예측된 대부분의 post들이 감정 분류에서 Anger 또는 Disgust의 예측값을 가짐
또한, 문장 속 해당 집단과 연관된 단어를 통해 target을 잘 검출함.
- MTL 모델로 학습하면 single task보다 성능이 좋으며, sencondary task는 primary task와 연관성이 높을 수록 좋음.
- Hate speech detection에는 target identification이 성능 향상에 도움을 많이 줌
- 하지만 학습해야할 파라미터 양이 훨씬 많아 real-time detection에는 활용이 힘들 것으로 예상
728x90반응형'Deep Learning' 카테고리의 다른 글